
티스토리 뷰
기본 문법 : https://colab.research.google.com/drive/1oXGdB4aPcGXDvvXRnovBg0UJbIS5c9eF#scrollTo=dYN_yvezZwmF
[학습 단계]
- 라이브러리 가져온다 import (torch,torchvision,matplotlib)
- GPU 사용 설정 random value를 위한 seed 설정
- 학습에 사용되는 parameter 설정 learning_rate,training_epochs,batch_size,etc)
- 데이터셋을 가져오고(학습에 쓰기 편하게) loader 만들기
- 학습 모델 만들기(class CNN(torch.nn.Module))
- Loss function(Criterion)을 선택하고 최적화 도구 선택(optimizer)
- 모델 학습 및 loss check(Criterion의 output)
- 학습된 모델의 성능을 확인한다.
[기본 단어]
- Epoch: 전체 데이터를 한번 다 보는걸 1바퀴라고 했을때, 몇 바퀴 돌 것인지를 나타낸다.
- Batch Size : 하나의 Mini-batch의 크기(mini-batch의 데이터 개수). 즉 전체 dataset 크기를 mini-batch의 개수로 나눈것.
- Iteration : 전체 데이터수와 mini-batch size에 따라 자동 결정된다.
- Learning Rate : 미리 지정한 횟수의 epoch가 지날때마다 lr을 감소시켜준다., lr이 매우 작을 경우, global minimum이 아닌 local minimum을 그래프의 최저점으로 인식할 수 도 있다.
- Layer : Model 또는 Module을 구성하는 한개의 층, Convolutional Layer,Linear Layer
- Module : 1개 이상의 Layer가 모여서 구성된 것, Module이 모여 새로운 Module을 만들 수 있다.
- Model : 최종적으로 원하는 것.

- Multi-Class Classfication : Multi-Class Classification은 여러 샘플(이미지)에서 C개의 클래스 중 하나의 클래스로 분류하는 문제로 생각할 수 있습니다.
각 샘플(이미지)은 클래스 C 중 하나로 분류될 수 있습니다.
해는 0번, 즉 [1 0 0] (원핫인코딩),
달은 1번, [0 1 0],
구름은 2번, [0 0 1]
으로 분류될 수 있다는 말입니다.
CNN은 s(scores) 벡터를 출력하고, one hot 벡터인 타겟(ground truth) 벡터 t와 매칭이 되어 loss값을 계산할 것입니다.
- Multi-Label Classficiation :여러 샘플(이미지)에서 각 샘플 마다 있는 클래스 들을 여러 클래스로 레이블하는 문제입니다.
위의 그림 중 오른쪽 그림을 참고하시면 됩니다.
각 샘플은 여러 개의 클래스 객체(object)를 가질 수 있습니다.
타겟 벡터 t는 하나 이상의 positive클래스를 가질 수 있고 [1 0 1] 처럼 인코딩 될 수 있습니다.
[기본 함수]
- torch.nn 함수
import torch.nn
nn은 Neural Network의 약자로 torch의 nn라이브러리는 Neural Network의 모든 것을 포괄하고, DL의 가장 기본이 되는 Linear Model도 nn.Linear클래스를 사용한다.
nn.Module은 모든 Neural Network Model의 Base Class이다. Neural Network Model은 nn.Module의 subclass이다.
nn.Module을 상속한 어떤 subclass가 Neural Network Model로 사용이 되려면 다음 두 메서드를 override 해야한다.
nn.Module 이란? 모든 PyTorch 모델의 base class
nn : Neural Network의 약자로 Neural Network의 모든 것을 포괄하고 Deep Learning의 가장
nn.Module에 내장된 method들은 모델을 추가 구성/설정 하거나, train/eval(test) 모드 변경, cpu/gpu 변경, 포함된 module 목록을 얻는 등의 활동에 초점을 맞춤
import torch.nn as nn
import torch.nn.functional as F
class Model_Name(nn.Module): -> torch.nn.Module 상속 필요, __init()__과 forward()를 override 해야한다.
def __init__(self): -> __init()__ : Model에 사용될 구성 요소들을 정의 및 초기화
super(Model_Name, self).__init__()
self.module1 = ...
self.module2 = ...
"""
ex)
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
"""
def forward(self, x): -> init()에서 정의된 요소들을 연결하여 모델을 만든다.
x = some_function1(x)
x = some_function2(x)
"""
ex)
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
"""
return x- numpy : Scientific computing과 관련된 여러 편리한 기능들을 제공해주는 라이브러리
- torch.utils.data : Mini batch 학습을 위한 패키지
- torchvision : PyTorch에서 이미지 데이터 로드와 관련된 여러가지 편리한 함수들을 제공하는 라이브러리이다.
- matplotlib.pyplot : 데이터 시간화를 위한 다양한 기능을 제공하는 패키지이다.
- torch.Tensor :
- 다차원 배열을 처리하기 위해 가장 기본이되는 자료형
- NumPy의 ndarray와 거의 비슷하지만, GPU연산을 함으로써 computing power를 극대화 시킬 수 있다. (딥러닝시 사용하는 이유)
- 기본텐서 타입(Default Tensor Type)으로 32비트의 부동소수점 torch.Float.Tensor으로 되어있다.
- NumPy의 ndarray와 마찬가지로 브로드캐스팅 적용이 가능하다.
- 브로드 캐스팅이란? 두 행렬의 곱셈을 할때, A와 B의 마지막차원이 일치해야한다. 이를 위해 파이토치에서 서로 크기가 다른 행렬들이 사칙연산을 수행할 수 있도록 자동으로 크기를 맞춰서 연산을 수행하게 해준다.
- nn.Sequential 함수 : 여러 module들을 연속적으로 연결하는 모델
- requires_grad : "학습된 모델의 성능을 Test할 때, torch.Tensor의 requires_grad를 True로 만들어 gradient를 계산하여 업데이트를 해주어야 한다." → false 왜일까

- nn.Conv2d : padding 사용하는 함수
- nn.MaxPool2d : polling 사용하는 함수
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
이 경우 model(x)는 nn.ReLU(nn.Conv2d(20,64,5)(nn.ReLU(nn.Conv2d(1,20,5)(x))))와 같음.
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))[Model]
- 선형 회귀 모델 구현 : nn.Linear()는 입력의 차원, 출력의 차원을 인수로 받습니다.
model = nn.Linear(1,1) : 모델을 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1.
- 문제
다음과 같이 512개의 hidden layer 뉴런으로 구성된 Multilayer Perceptron(MLP) 모델을 이용하여, 28*28의 MNIST 데이터를 10개의 class로 구분하는 모델을 만드려고 한다.
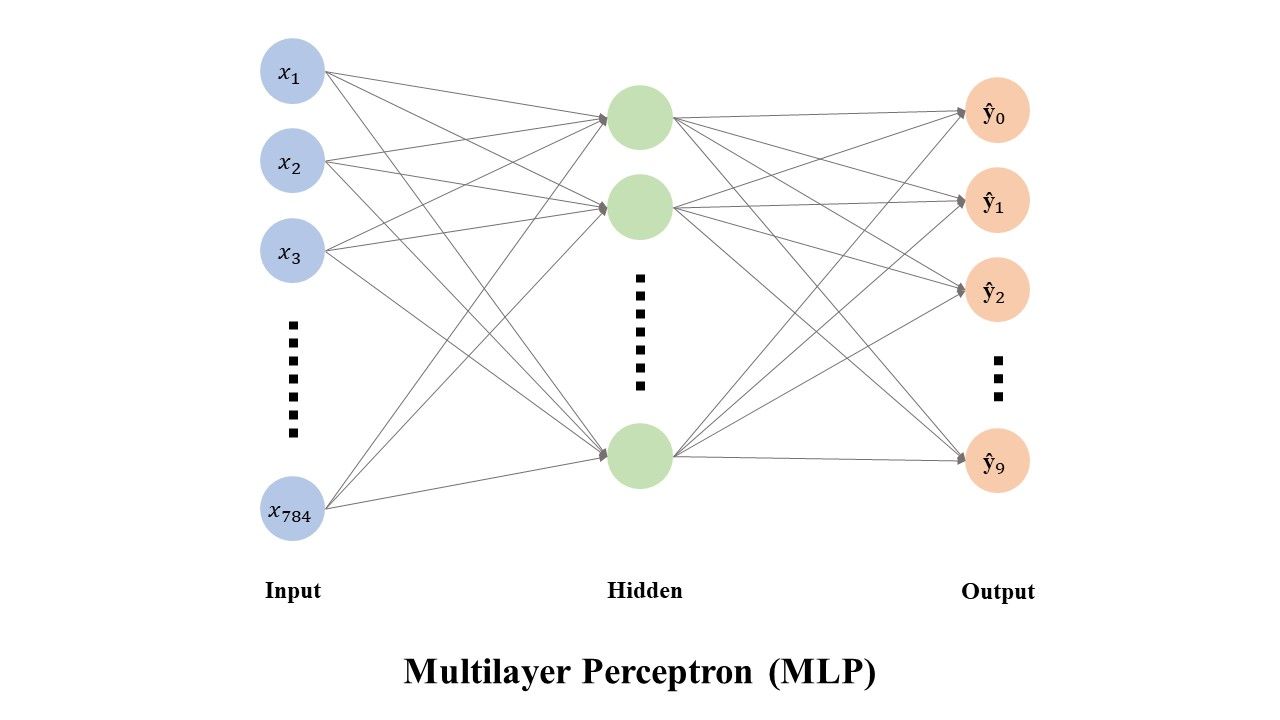
- Optimizer 구현
- optim.SGD (확률적 경사 하강법)
N = None
M = None
H = None
class MLP(nn.Module):
def __init__(self,N):
super(MLP,self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(M,H),
nn.BatchNormld(H),
nn,ReLU()
)
self.layer2 = nn.Sequential(
nn.Linear(H,N)
)
def formward(self,x):
x = x.view(x.size(0),-1_
x_out = self.layer1(x)
x_out = self.layer2(x_out)
return nn.softmax(x_out)
위 코드에서 정수 N, M, H에 들어갈 숫자의 조합으로 알맞은 것은?
→ 예시에서는 28*28 데이터를 512개로 출력하므로 self.layer1 = nn.Sequential(nn.Linear(28*28,512))
layer1에서 한것을 batchsize에 맞게 normld 진행해야 하므로 layer2에서 nn.Linear(512,10)
[ Model - Loss Function]
- Pytorch Loss Function 정리
Cross Entropy Losss는 Linear Model을 통해 최종값이 나오고, softmax를 통해 이 값들의 총합이 1이 되도록한다. → softmax와 cross entropy를 합쳐놓은것
BCELoss는 만약 class가 2개인 binary case의 경우에는 BCELoss를 사용한다. (softmax를 포함하는게 아닌 Cross Entropy만 구하기 때문에 loss를 사용하는 경우에는 softmax 또는 다른 activataion function을 따로 적용해주어야 한다.)
- 모델의 손실함수( Cross-Entropy Loss, Categorical Cross-Entropy Loss, Binary Cross-Entropy Loss..) : criterion = BCELoss()와 출력층의 활성화 함수(sigmoid,softmax..): y_pred = nn.Sigmoid(self.linear(x))가 최적의 조합
- BCE Loss : Sigmoid activation 뒤에 Cross-Entropy loss를 붙인 형태로 주로 사용하기 때문에 Sigmoid CE loss라고도 불립니다. → Multi-label classification에 사용됩니다.
- CrossEntropyLoss : Softmax activation 뒤에 Cross-Entropy loss를 붙인 형태로 주로 사용하기 때문에 Softmax loss 라고도 불립니다. → Multi-class classification에 사용됩니다.
- cost = F.mse_loss(prediction,y_train) =>
cost = criterion(hypothesis,Y)
cost = (y_one_hot * -torch.log(F.softmax(hypothesis,dim=1))).sum(dim=1).mean()
cost = F.cross_entropy(prediction, y_train) #y_train = (m,)
'DL' 카테고리의 다른 글
| [DL] 네이버 edwith AI/딥러닝 입문을 위한 학습 콘텐츠 추천에 따른 수업 + 3BlueBrown 강의 (2) | 2023.04.14 |
|---|---|
| [DL] Custom data 결과 (0) | 2023.04.14 |
| [DL] Yolo일지 (0) | 2023.04.14 |
| [DL] Yolo개념 정리 (0) | 2023.04.14 |