
티스토리 뷰
- yolo v3 github있는걸로 한번 해봤을때 주황버섯인형이 사람으로 가끔 나온다.

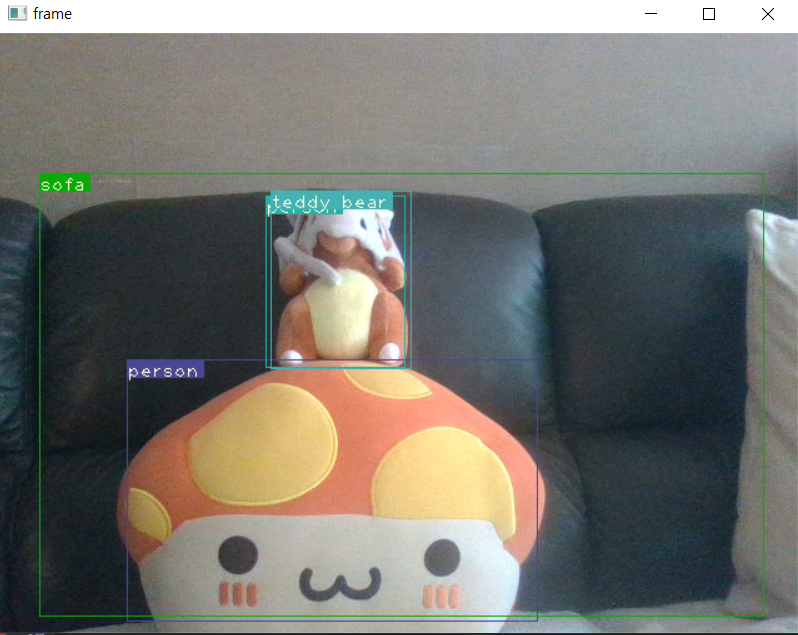
- 핸드폰 화면을 비줘서 했을때 판정을 한다

- 정확도가 좀 떨어지는것같아서 yolov3에서 yolov5로 변경하고 진행했다.


- 잘되는것같아서 이번엔 https://public.roboflow.com/object-detection/ 에서 labeling된 물고기 데이터를 가져와서 customized 해보았다.
→ \yolov5\data\coco128 의 class의 nc수와 names 변경 및 data path변경
- 학습을 되었지만 detect 데이터셋을 물고기를 가져와야하나 잘못 가지고 와서 detect하고 있었다..
→ weight가 초기에 yolov5s로 세팅이 되어있어서 학습된 최고의 weight 결과값인 best.pt를 넣어서 진행해야함.(학습시킬때마다 학습시킨 최적의 가중치가 다를 수 있으므로 매번 해당 학습 결과 폴더(exp)에서 가져와야한다.)


- detect dataset은 물고기인데, 실제 탐지는 기존 yolo모델로 되었다
(펭귄을 person으로 나온다니 충격)
→ weight를 학습한 best 가중치로 가져와야하는데 실수로 yolov5s로 넣었다..(위의 실수와 같음 위: detect의 가중치 안바꿈, 아래: train의 가중치 안바꿈)

- 학습 후 detect시 아무런 결과값이 출력되지 않아 확인해보니 source 경로를 잘못잡았었다.
data/images -> data/images/train2017/valid
- 학습을 했을때 detect 정확도가 높지 않았다.


- 아래와 같은 조치를 취함
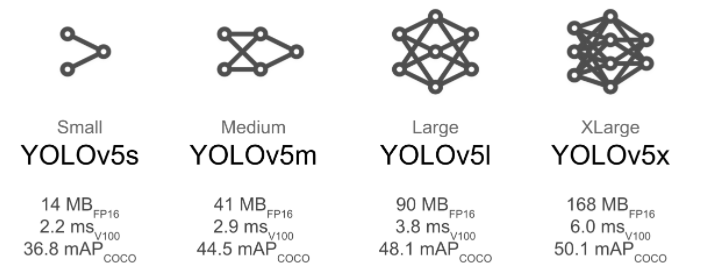
weight : yolov5s →yolov5l : 모델이 깊고 복잡하다는건(l가 제일 복잡) 그만큼 많은 데이터를 필요,성능 우수할 수 있으나 우리가 적정량의 데이터를 가지고 적정한 퀴즈를 푼다 했을때 꼭 무겁고 큰 구조만 좋은게 아니여서 s,m,l 모델들을 모두 돌려봄
- yolo v5는 s, m, l, x의 4가지 버전이 있음
- s가 가장 가벼운 모델
- x가 가장 무거운 모델
- 당연히 s가 성능이 제일 낮지만 FPS가 가장 높고, x가 성능이 제일 높지만 FPS는 가장 낮습니다.
- 자세히 보는 만큼 느리고 대충 보는만큼 빠르다
Gpu의 한계때문에 아래와 같이 train의 setting 변경
epochs : 300 -> 100
batch size : 16 →8 (batch size는 train시에 속도가 느려서 하는것, detect는 상관없다(한잘씩 프레임 단위로 추론하기 때문)
image size : 640 -> 320 (이미지 size가 640 해상도가 클수록 -> 모델 학습 증가, 판단 증가 but 속도 느려짐)


+ detect는 이미지 사이즈와 관련있어서 320x320(320x320x3 = 307200 -> 640x640(640x640x3 채널 = 1228800) 변경시 속도가 느려진다.
+ train의 목표: 좋은 가중치를 구해서 모델에 넣는다.
새로운 custom data로 변경 결과내용
Data양이 적어서 정확도가 떨어진다고 판단, 새로운 custom data로 변경함. 2576개 train image, 736개 validataion image.
*특이 사항
2차 시도(회사) : epoch:200 image size:320 batchsize: 16 (train : 16, val:16) → 정확도가 이전보다 높아졌지만, 여전히 잘못 탐지하는 부분들이 있음
161x16=2576 ,23x16 = 368 -> val의 batchsize가 안맞는다.
*batch size가 validation에 안맞는이유 : yolo의 경우 multiple gpu를 사용하기때문에 홀수일 경우를 비추천한다고 한다. 버그인줄알고 찾던 내 하루가 날라갔다..
(https://github.com/ultralytics/yolov5/issues/2491)
그래서 validation시 "batch_size = batch_size // WORLD_SIZE * 2" 로 해서 2를 한번 더 나눠주기 때문에 validation이 /2가 된 상태에서 진행.(실제로는 모두 학습함).
but 왜 train은 "batch_size = batch_size // WORLD_SIZE * 2"을 따르지 않는지 질문할 예정
Epoch gpu_mem box obj cls labels img_size
199/199 0G 0.03224 0.05265 0.05606 27 320: 100%|██████████| 161/161 [18:19<00:00, 6.83s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 23/23 [01:33<00:00, 4.06s/it]
all 736 738 0.971 0.959 0.979 0.676
cat 736 251 0.993 0.968 0.984 0.759
dog 736 487 0.949 0.95 0.974 0.594



*Best 결과 값
5차 시도 : epoch:300 image size:320 batch size: 32 (train : 32, val:32) :세세한것까지 잡음. 학습제일 잘된것같다.
Epoch gpu_mem box obj cls labels img_size
299/299 0G 0.02592 0.04432 0.0248 41 320: 100%|██████████| 81/81 [17:36<00:00, 13.05s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 12/12 [01:34<00:00, 7.87s/it]
all 736 738 0.99 0.966 0.986 0.756
cat 736 251 1 0.976 0.986 0.828
dog 736 487 0.981 0.957 0.986 0.684



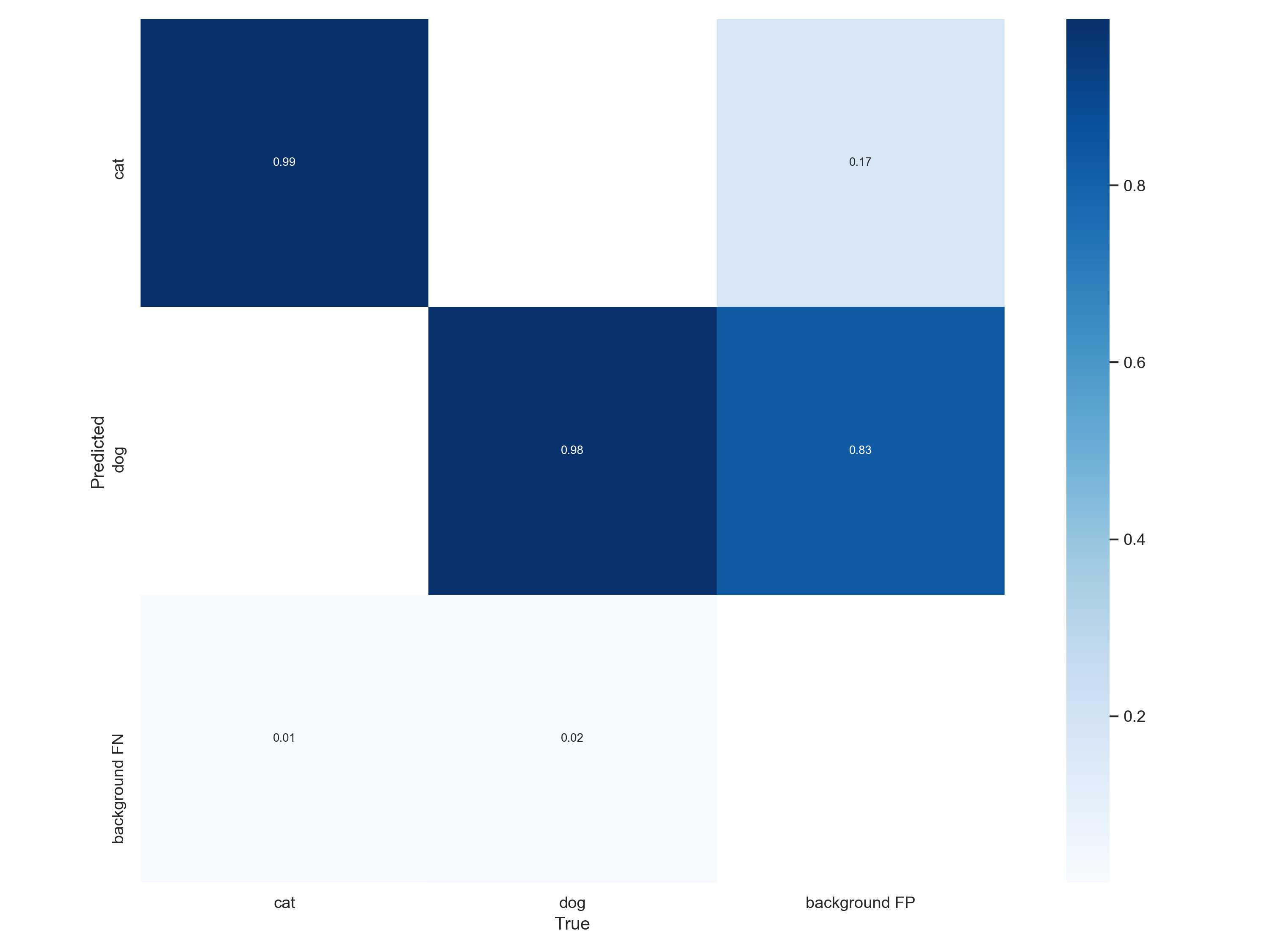



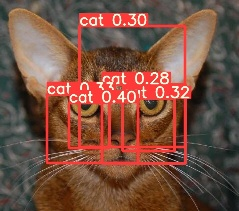



*결과에 대한 생각 및 조사
- loss값에 대한 표에서 train,val의 표가 꼭 겹치지 않아도 과적합이 아니다. → 결과값에 있는 epoch 100을 제외한 표들은 모두 데이터가 잘나왔다라는 뜻
- P,PR,R의 커브가 ㄱ 로 바로 떨어지는것은 epoch이 적어서 lr이 빠르게 학습했기 때문이다. → epoch이 300대로 늘어났을 경우에는 원만한 커브 모양이 나옴
- detect의 결과가 이상할 경우 image의 label이 잘 되어있는지 얼굴이 명확하지 않는 것들은 해당 image를 제거하는게 좋다.
- 0.83등 높은 수치로 detect하기 때문에 좋은 결과. 다만 %로 값을 바꾸면 좋을꺼같다.
- 1번같이 여러개가 나오는건 학습이 너무 자잘하게 이뤄져서이다. (맞는지 재확인 필요)
'DL' 카테고리의 다른 글
| [DL] 네이버 edwith AI/딥러닝 입문을 위한 학습 콘텐츠 추천에 따른 수업 + 3BlueBrown 강의 (2) | 2023.04.14 |
|---|---|
| [DL] Custom data 결과 (0) | 2023.04.14 |
| [DL] Yolo개념 정리 (0) | 2023.04.14 |
| [DL] Pytorch문법 (0) | 2023.04.14 |